论文阅读系列–RL篇
1. Reinforcement Learning in Medical Image Analysis: Concepts, Applications, Challenges, and Future Directions
一句话摘要: 医学影像分析对于医生来说有两大痛点: 低效、和个人经验偏差,而机器学习中的无监督和监督学习已经广泛应用,但强化学习的应用相较比较稀少,因此整理这个回顾性文章服务之后更多的研究。
论文之我问:
1.1 这个论文的动机是什么
众所周知,强化学习在近年来取得了长足的发展,但是却发现很难应用在临床应用上。一个主要的原因就在于,没有一个很好的基于计算机背景的相关文章的梳理。因此本文不是列举相关的强化学习模型,而是去了解如何将医学影像分析转化为强化学习问题。
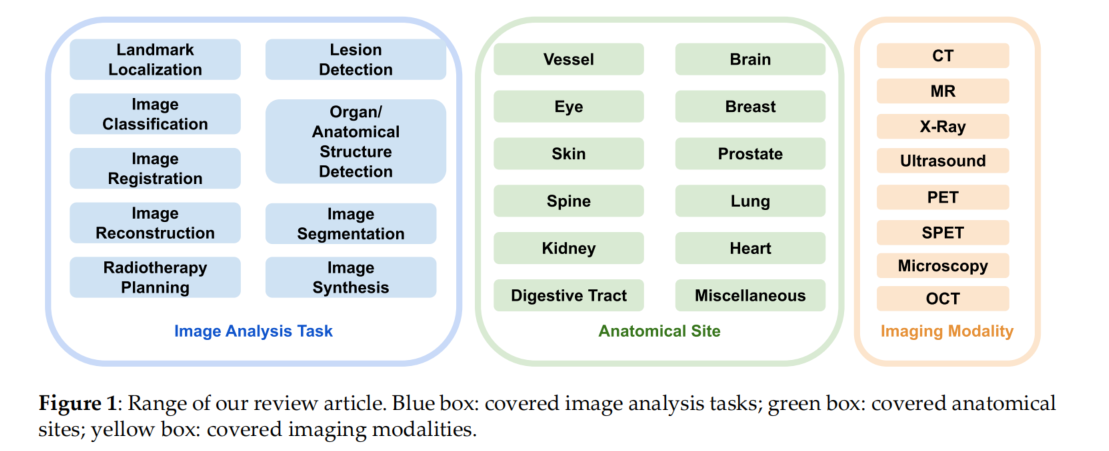
如图1所示评价文章的选取范围。蓝色的图片分析任务,绿色的是解剖部位,黄色的是图片模态
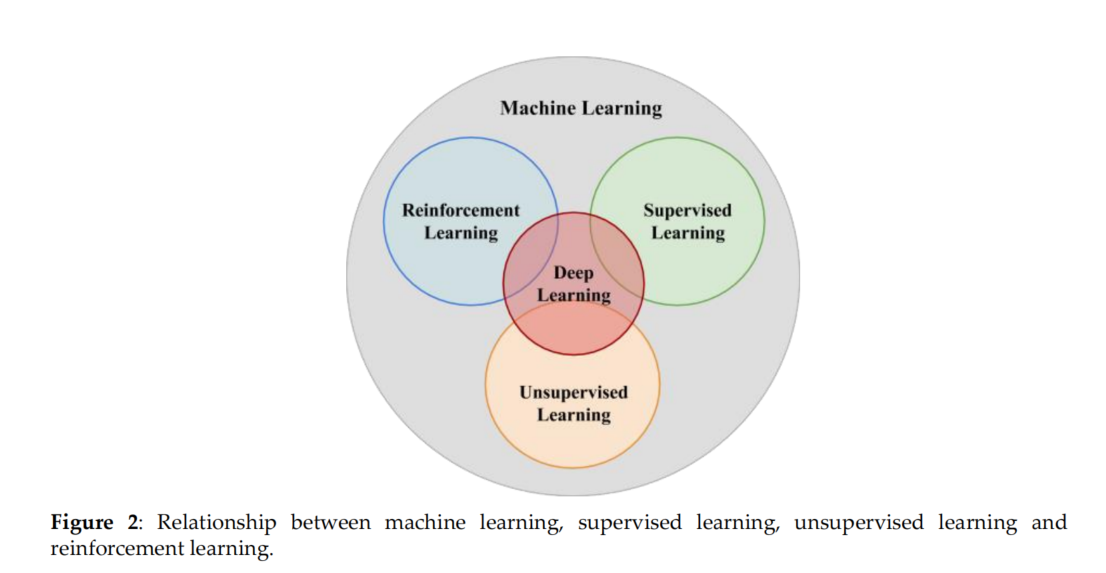
如图2所示。机器学习、有监督学习、无监督学习和强化学习之间的关系。
- 强化学习(RL)既不是有监督学习,也不是无监督学习。强化学习的目标是达到最大的预期累积奖励
强化学习的独特优势:
-
RL模型可以有效地从受监督的行动逐步指导的有限的注释中学习,而医疗数据往往缺乏大规模可访问的注释。
-
RL模型的偏见较小,因为它们不会从人类注释者制作的标签中继承偏差。
-
智能体(RL-agent)可以从顺序数据中学习,而学习过程是面向目标的。除了利用经验外,它还可以探索新的解决方案。在解决同样的问题时,RL甚至可以超过人类专家。
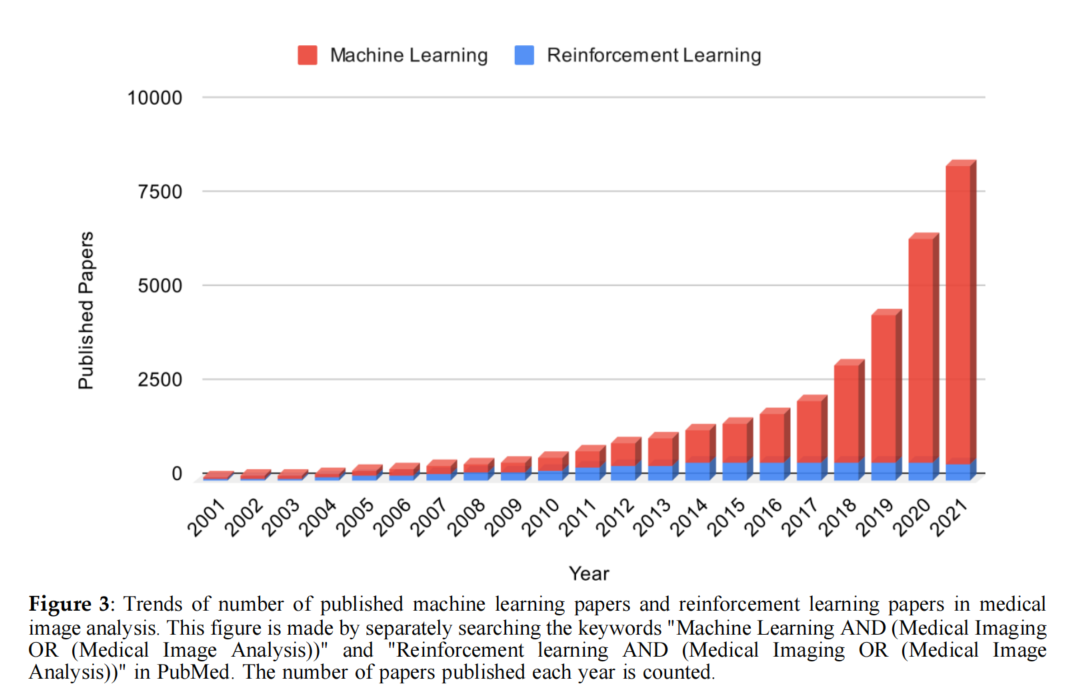
如图3所示,强化学习在医学分析领域开发技术发展的尝试很少。
1.2 这篇论文的研究框架是什么样的
1.2.1 研究论文的筛选
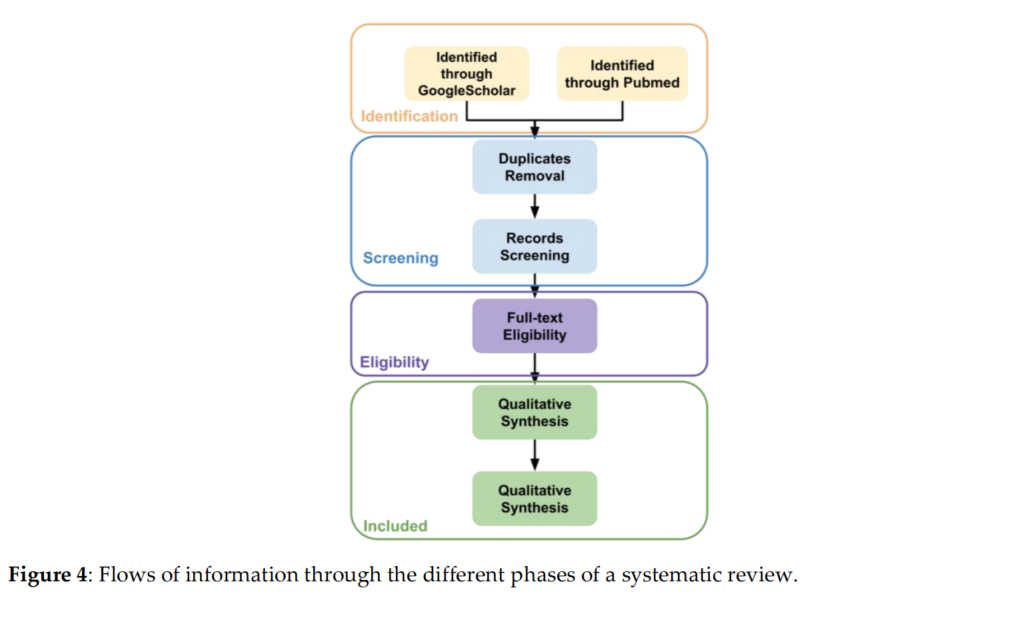
如图4所示,本文筛选的一个流程。
1.2.2 RL基本介绍
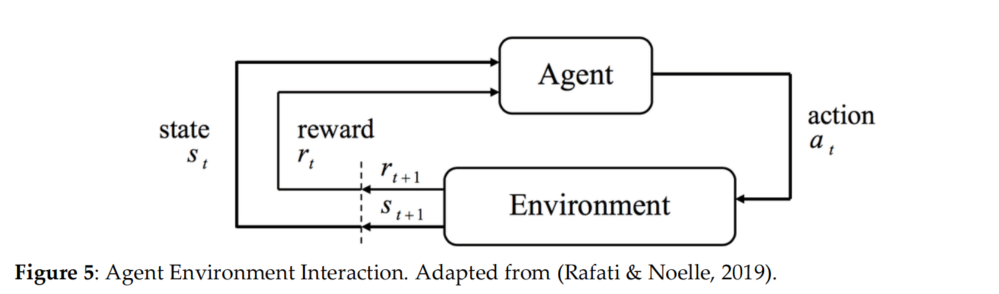
如图5所示,这个是一个智能体与环境交互的基本框架。
众所周知,RL有两种,model-based 和 model-free,而model-free可以进一步细分为value-based和policy-based
- model-based RL试图解释环境,并创建一个模型来模拟它。
- model-free 只会通过与环境互动并观察奖励来更新其策略。
- value-based: 适用于离散动作空间问题
- policy-based: 同时适用于离散的和连续的动作空间。
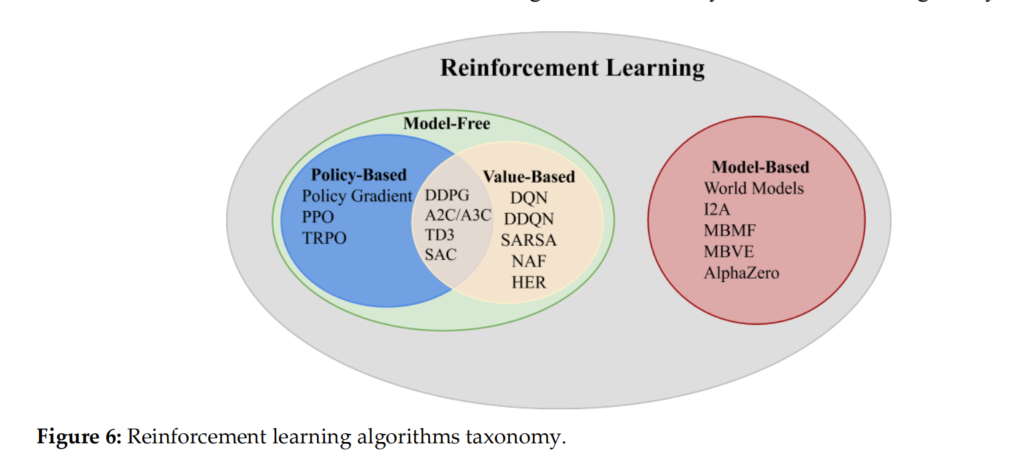
如图6所示,强化学习的分类。
1.2.3 RL 在医学影像分析中的应用
以下这些论文中最基本和最棘手的任务是在训练模型之前设计状态空间、动作空间和奖励空间。
Medical Image Detection
1. Landmark Detection
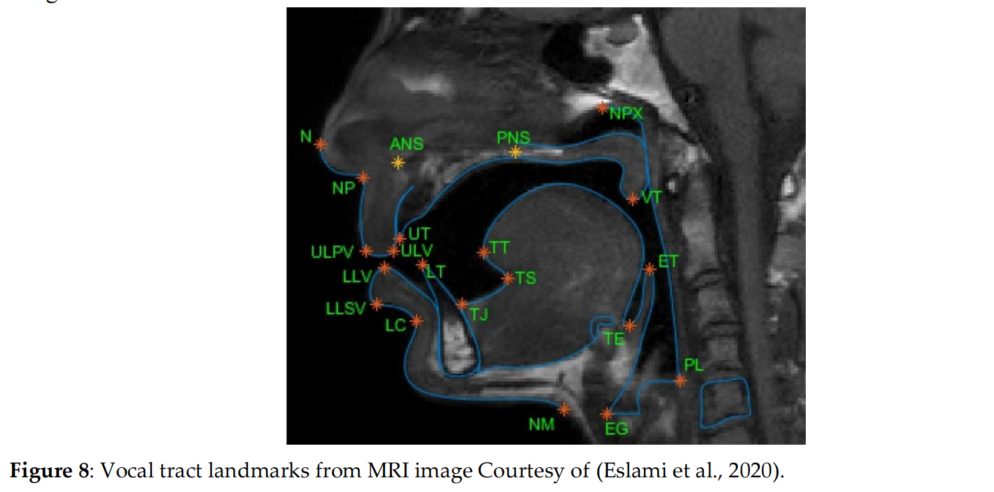
如图8所示,这个是一个MRI图像中声道标注的一个例子。
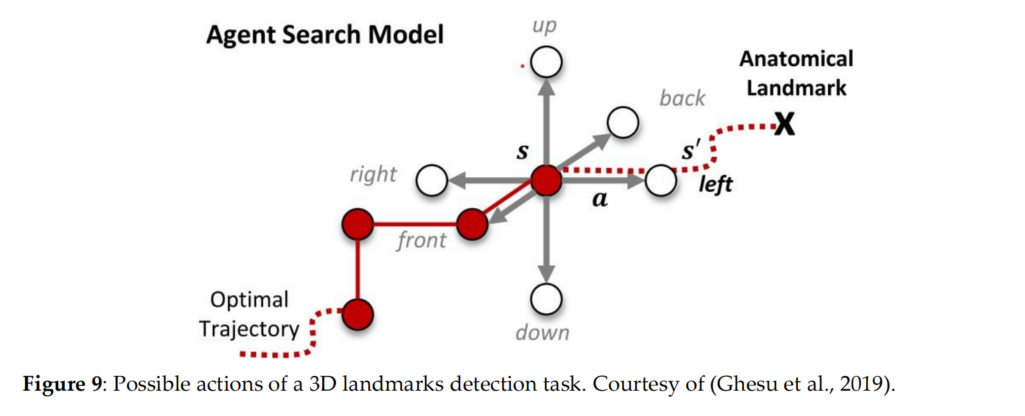
Ghesu et al., 2016最早提出把RL运用在Landmark Detection上。他对三个空间的设置如下:
$\overrightarrow{p_{GT}}$ 表示为解剖位置的位置,$\overrightarrow{p_t}$ 表示为当前时间的位置。
-
状态空间S:即所有可能的状态$s_t = I(\vec{p_t})$
-
动作空间A:即智能体所有可能的行动,如图9所示
-
奖励空间R:${ \overrightarrow{p_t} - \overrightarrow{p_{GT}} }_2^2 - { \overrightarrow{p_{t+1}} - \overrightarrow{p_{GT}} }_2^2$ 表示智能体向目的地移动的更近
上述做法的最大缺点是不是能在不同scale下进行使用,因此multi-scale DRL被提出了来(Ghesu et al., 2019). 如图10所示:
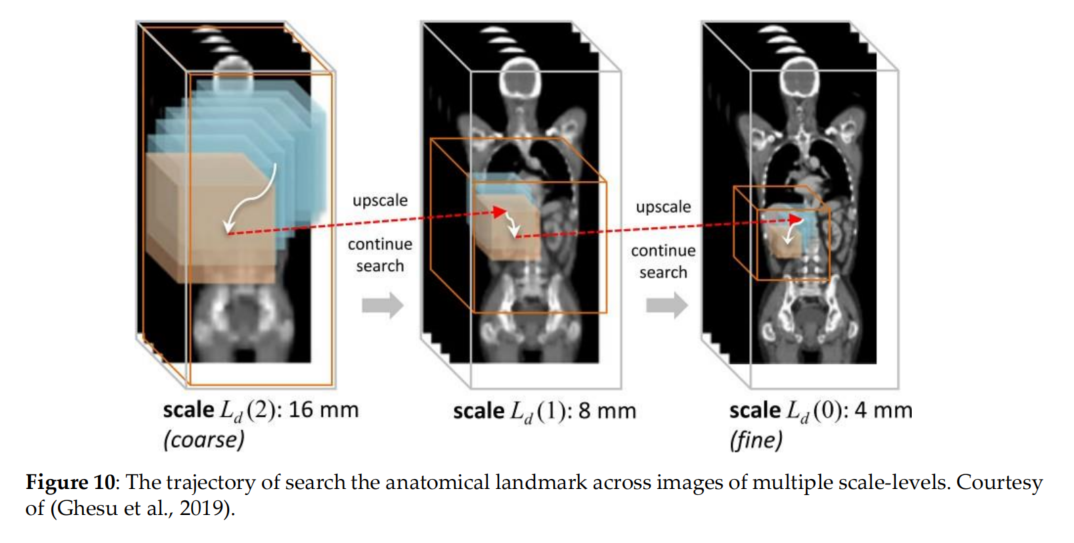
更多其他人的工作都将会整理在最后的表格中进行汇总。
2. Lesion Detection
目标检测也是一个医学领域的主流任务,并且其更好地可以帮助后续的分割任务。目前主流的深度学习方法依旧依赖于大量标记数据。受到Ghesu et al., 2016的启发,Maicas et al., 2017用DQN实现了乳腺活动性病变检测。
更多其他人的工作都将会整理在最后的表格中进行汇总。
3. Organ/ Anatomical Structure Detection
除了检测病变外,强化学习还可以应用于器官检测。
表格1
Medical Image Segmentation
1. Threshold Determination
(Sahba et al., 2006)首次使用了Q-learning
2. Pre-locate the Segmentation Region
(Yang et al., 2020) 首次使用DQN分配导管的粗位置,然后通过Dual-UNet进行基于智能体的分割。
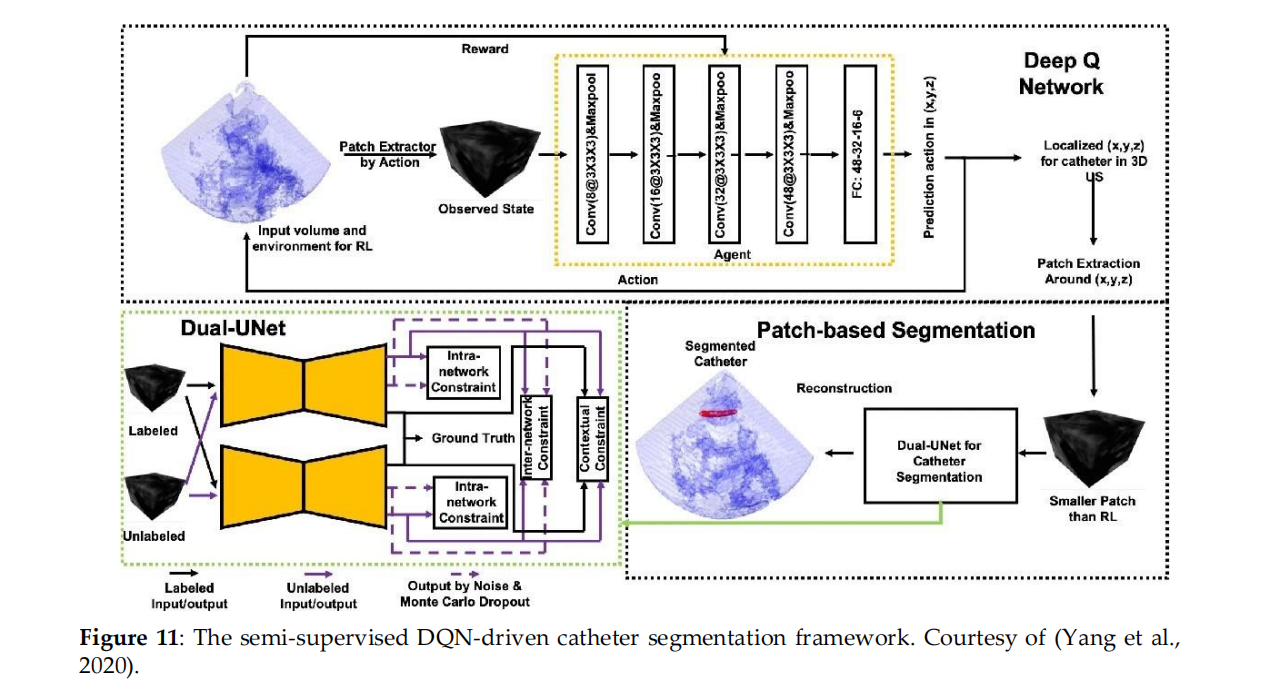
如果智能体离开目标,代理会给予负奖励;否则,前进是积极的奖励,如果站着不动则没有奖励。
如图11所示。
3. Hyperparameters optimization
RL代理也可以用于优化现有的医学图像分割管道,搜索最优的神经网络结构。
4. Segmentation as a Dynamic Process
“Show-Learn- Act” workflow。有用户指导下的分割学习
1.3 这篇论文的实验效果
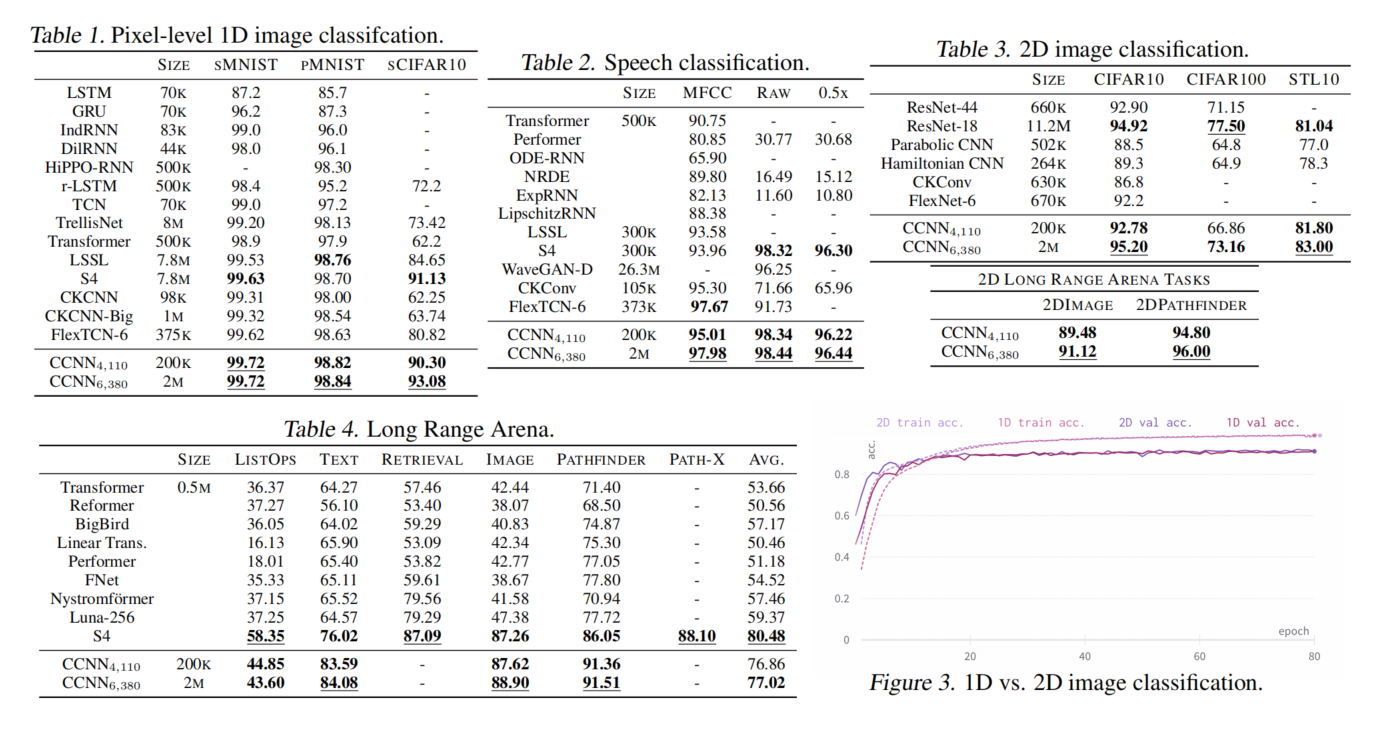
CCNN在多种任务上都表现良好,并在一些任务上达到了SOTA
1.4 代码参考
https://github.com/david-knigge/ccnn.*
